Do que se alimentam?



Vimos anteriormente que podemos abstrair redes neurais como funções, e portanto esperam certas entradas e produzem saídas, mas o que são essas entradas e saídas exatamente? Tanto as entradas como saídas são tensores.
Nesta seção iremos discutir o que são tensores e como manipulá-los com Numpy.
O que são tensores?
Tensores são vetores de diferentes dimensões. Você já conhece tensores, os mais comuns tem nomes próprios:
Um tensor 0-dimensional é denominado escalar:
escalar_a = 1.0
escalar_b = -12
escalar_c = 1e-8
Um tensor uni-dimensional é um vetor (array):
vetor_a = [1.0]
vetor_b = [1.0, 2.0, 3.0]
vetor_c = [-0.33, 0.421, -789.12, 11.0, 53421093.1231, -123.1]
Um tensor bi-dimensional é uma matriz (Em Python uma lista de listas):
matriz_a = [[1.0]] # 1 x 1
matriz_b = [[1.0], [2.0], [3.0]] # 3 x 1
matriz_a = [[1.0] * 10, [2.0] * 10, [3.0] * 10] # 3 x 10
Um tensor é qualquer vetor com N-dimensões (por exemplo, um cubo é um tensor de 3 dimensões). Ainda pensando dessa forma, poderíamos imaginar um tensor 4-dimensional como um array de cubos; um tensor 5-dimensional seria uma matriz de cubos; um tensor 6-dimensional seria um cubo de cubos, e assim por diante...

tensor_a = 1.0
tensor_b = [1.0, 2.0, 3.0]
tensor_c = [[1.0]]
tensor_d = [[[1.0], [2.0], [3.0]], [[1.0], [2.0], [3.0]], [[1.0], [2.0], [3.0]]] # tensor com dimensoes: (3, 3, 1)

Já os matemáticos que gostam de cachorros, preferem pensar em tensores da seguinte forma:

Visão Pythonica: Numpy!
Numpy é uma biblioteca em Python para manipulação eficiente de tensores. Numpy facilita nossa vida de várias formas... desde simplificando obter as dimensões de um tensor até a implementação de varias funções para manipulação de tensores de forma eficiente.
De acordo com as próprias palavras da numpy.org (tradução livre):
Numpy é um pacote fundamental pra computação científica com Python.
Entre outras coisas, o Numpy possui:- um podereso ferramental para manipulação de arrays multi-dimensionais- funções de broadcasting sofisticadas (veremos isso já já)
- ferramentas para integração de código Fortran e C/C++ (por baixo dos panos pra gente não ter que se preocupar)
- utilidades para álgebra linear, tranformação de Fourier e números aleatórios
Para usar o numpy, tudo que precisamos é importá-lo:
!pip3 install numpy
# pq numpy é muito grande pra ficar digitando toda hora
import numpy as np
Manipulando tensores
Até então Numpy parece ser um wrapper com umas funções pra facilitar iteragir com tensores... mas... o que mais nós podemos fazer com numpy?
Bem eu disse que numpy possui "um podereso ferramental para manipulação de arrais multi-dimensionais".
O que danado isso significa?
MÁGICA!
Vamos começar criando um array numpy. Um array numpy parece igualzinho a uma lista em python, mas não se engane, não é!
list_py = [1, 2, 3]
# Array numpy descolado
vector_np = np.array([1, 2, 3])
print('list python:', type(list_py), list_py)
print('vetor numpy', type(vector_np), vector_np)
Humm... okay, vamos tentar dar um append nas listas...
list_py.append(1)
# Erro!
try:
vector_np.append(1)
except Exception as e:
print(f'Error: {type(e)}, Message: {e}')
Não existe append diretamente em um vetor numpy... Mas você pode fazer append via numpy...
vector_np = np.append(vector_np, 1)
vector_np
Mas fica aquele velho ditado: não é porque você pode que você deve!
Normalmente não executamos append em vetores numpy, eles já nascem prontinhos e realizamos operações entre vetores (adição, multiplicação, transposição, ...). Não adicionamos ou removemos valores de vetores numpy.
Por que? Em geral isso é ineficiente, olha o exemplo abaixo.
import time
N = 100000
# Usando uma lista python e depois convertendo para numpy
def time_to_create_vector_py():
start = time.time()
l = []
for i in range(N):
l.append(i)
l = np.array(l)
return time.time() - start
# Usando um vetor numpy desde o inicio pq sou teimoso
def time_to_create_vector_np():
start = time.time()
l = np.array([])
for i in range(N):
l = np.append(l, i)
l = np.array(l, dtype=int)
return time.time() - start
print('Tempo utilizando lista: %.3f (s)' % time_to_create_vector_py())
print('Tempo utilizando numpy: %.3f (s)' % time_to_create_vector_np())
Ta, então uma vez que a gente cria um array numpy, normalmente não alteramos ele via operações convencionais de modificação de lista.
Se você para pra pensar isso faz todo sentido: já que um array numpy não é uma lista python, mas sim um tensor.
- Vamos chamar o número de dimensões de um tensor de ndim;
- O shape é uma tupla de inteiros do tamanho do ndim que fornece número de elementos ao longo de cada dimensão.
vector_np.ndim
vector_np.shape
E se em vez de um array tivermos um escalar?
scalar_np = np.array(3)
# 0 pq não temos nenhuma dimensão
print(scalar_np.ndim)
# Vazia
print(scalar_np.shape)
E matrizes?
matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
matrix_np = np.array(matrix)
print(matrix_np.ndim)
# (3, 3) pq é uma matrix 3x3
print(matrix_np.shape)
E outros tensores?
tensor_py = [[[1.0], [2.0], [3.0]], [[1.0], [2.0], [3.0]], [[1.0], [2.0], [3.0]]] # tensor com dimensoes: (3, 3, 1)
tensor_np = np.array(tensor_py)
print(tensor_np.ndim)
print(tensor_np.shape)
Esse código python quebra porque não da pra somar inteiro com lista.
try:
1 + matrix
except Exception as e:
print(e)
Mas pensa um pouco... pensando em soma de tensores... o código faz "sentido", parece que 1 deveria ser somado a cada elemento da lista.
Bem que dava pra python ser mais esperto e entender que o que a gente quer é na verdade propagar o 1 por toda a matriz somando cada elemento a 1.
Essa propagação é justamente o que chamamos de broadcasting. Que é a ideia de que vetores de tamanhos e formatos diferentes são compatíveis para certas operações em alguns casos!
matrix_np
# Somar um valor a todos os elementos de uma matriz nunca foi tao fácil!
1 + matrix_np
O que acontece se tentarmos somar um vetor de tamanho 3 a matriz?
[1, 2, 3] + matrix_np
Sem broadcasting, como faríamos a operação acima usando numpy?
v = np.array([1, 2, 3])
print(v)
# Cria 3 copias de v e empilha
vv = np.tile(v, (3, 1))
print('-' * 10)
print(vv, vv.shape)
# Soma
print('-' * 10)
print('Soma')
matrix_np + vv
O broadcasting nos permite obter o mesmo resultado sem precisar criar cópias do vetor. Sendo mais eficiente tanto em tempo quanto em memória. Além de simplificar bastante a nossa vida.
try:
[1, 2] + matrix_np
except Exception as e:
print(e)
O que aconteceu foi que os formatos dos vetores não são compatíveis, então numpy não conseguiu realizar broadcast corretamente para realizar a operação.
O que é até intuitivo, o que danado a gente estava esperando somando um vetor de tamanho 2 com uma matriz 3x3?
Existe um algoritmo que podemos utilizar pra saber se o broadcast vai dar certo:
- Recebemos a e b
- Percorremos os formatos de a e b de trás pra frente
- Para cada uma das dimensões dim_a e dim_b deve ser verdade que:
- dim_a == dim_b ou dim_a == 1 ou dim_b == 1
Pense um pouco a respeito... e tende adivinhar os formatos de cada vetor e se os pares são passíveis de broadcast:
- Caso 1: [1, 2] e [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
- Caso 2: [1] e [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
- Caso 3: [[[[[1]]]]] e [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
- Caso 4: [1, 2] e [[1, 2], [4, 5], [7, 8]]
O código da checagem e soluções seguem logo abaixo.
def is_broadcast_possible(a, b):
# Oferecimento: https://stackoverflow.com/questions/47243451/checking-if-two-arrays-are-broadcastable-in-python
a, b = np.array(a), np.array(b)
print('Formato de a:', a.shape)
print('Formato de b:', b.shape)
return all((m == n) or (m == 1) or (n == 1) for m, n in zip(a.shape[::-1], b.shape[::-1]))
is_broadcast_possible([1, 2], [[1, 2, 3], [4, 5, 6], [7, 8, 9]])
is_broadcast_possible([1], [[1, 2, 3], [4, 5, 6], [7, 8, 9]])
is_broadcast_possible([[[[[1]]]]], [[1, 2, 3], [4, 5, 6], [7, 8, 9]])
is_broadcast_possible([1, 2], [[1, 2], [4, 5], [7, 8]])
Broadcast é possível para diferentes operações e não apenas soma:
a = np.array([1, 2])
b = np.array([[1, 2], [4, 5], [7, 8]])
print('a + b')
print(a + b)
print('a * b')
print(a * b)
np.zeros((3, 3)) # argumento é o shape do array.
np.ones((3, 3))
np.full((3, 3), 7)
np.eye(3) # matriz diagonal.
np.diag([1, 2, 3]) # matriz diagonal com valores específicos.
np.diag([1, 2, 3], k=1) # k = offset da diagonal
np.mgrid[1:4, 1:4] # similar ao meshgrid no Matlab
np.random.rand(3, 3) # distribuição aleatória
np.random.randn(3, 3) # distribuição normal (gaussiana)
np.random.randint(1, 10, (3, 3)) # número aleatórios inteiros de 1 a 10
np.arange([start,] stop[,step,], dtype=None)
np.arange(10)
np.arange(1,10)
np.arange(1, 10, 0.5)
np.arange(1, 10, 3)
np.arange(1, 10, 2, dtype=np.float64)
np.linspace(start, stop, num=50, endpoint=True, retstep=False)
np.linspace(1, 5, num=10)
np.linspace(0, 2, num=4)
np.linspace(0, 2, num=4, endpoint=False)
ds = np.array([[1,2,3],[4,5,6],[7,8,9]])
ds.ndim
ds.shape
ds.size # número total de elementos
ds.dtype # tipo dos elementos guardados
ds.itemsize # qtde de bytes por valor
ds.size * ds.itemsize # espaço total ocupado em memória (em bytes)
data_set = np.random.random((2, 3))
data_set
np.max(a, axis=None, out=None, keepdims=False)
np.max(data_set)
np.max(data_set, axis=0)
np.max(data_set, axis=1)
np.min(a, axis=None, out=None, keepDims=False)
np.min(data_set)
np.mean(a, axis=None, dtype=None, out=None, keepdims=False)
np.mean(data_set)
np.median(a, axis=None, out=None, overwrite_input=False)
np.median(data_set)
np.std(a, axis=None, dtype=None, out=None, ddof=0, keepdims=False)
np.std(data_set)
np.sum(a, axis=None, dtype=None, out=None, keepdims=False)
np.sum(data_set)
np.prod(a, axis=None, dtype=None, out=None, keepdims=False)
prod = 1
for e in data_set.flatten():
prod *= e
np.prod(data_set), prod
prods = []
for v in data_set:
prod = 1
for e in v:
prod *= e
prods.append(prod)
np.prod(data_set, axis=1), prods
np.cumsum(a, axis=None, dtype=None, out=None)
np.cumsum(data_set) # soma acumulada.
np.cumprod(a, axis=None, dtype=None, out=None)
np.cumprod(data_set) # multiplicação acumulada.
np.reshape(data_set, (3, 2))
np.reshape(data_set, (6, 1))
np.reshape(data_set, 6)
np.ravel(a, order='C')
np.ravel(data_set)
data_set.flatten() # igual ao ravel
data_set = np.random.randint(1, 10, (5, 5))
data_set
data_set[1] # segunda linha
data_set[1][0] # segunda linha, primeira coluna
data_set[1, 0] # equivalente a de cima
Quando você indexa matrizes numpy usando slicing, a matriz resultante sempre será um subarray da matriz original. Por outro lado, a indexação de matrizes por inteiros permite que você construa matrizes arbitrárias usando os dados de outra matriz. Aqui está um exemplo:
a = np.array([[1,2], [3,4], [5,6]])
a
a[[0, 1, 2], [0, 1, 0]]
np.array([a[0, 0], a[1, 1], a[2, 0]]) # equivalente ao de cima
Boolean array indexing lets you pick out arbitrary elements of an array. Frequently this type of indexing is used to select the elements of an array that satisfy some condition. Here is an example:
a = np.array([[1,2], [3,4], [5,6]])
a
bool_idx = (a > 2)
print(bool_idx)
print(a[bool_idx])
print(a[a > 2])
data_set[2:4] # terceira e quarta linhas
data_set[2:4, 0] # terceira e quarta linhas, primeira coluna
data_set[2:4, 0:2] # terceira e quarta linhas, primeira e segunda coluna
data_set[:, 0] # todas as linhas, primeira coluna
data_set[:, 0:10:2] # 1ª, 3ª, 5ª, 7ª e 9ª colunas para todas as linhas
data_set[::]
data_set[::2] # 1ª, 3ª e 5ª linha, todas as colunas
x = np.array([[1,2], [3,4]])
y = np.array([[5,6], [7,8]])
print(x+y)
print(np.add(x,y))
print(x - y)
print(np.subtract(x, y))
print(x * y)
print(np.multiply(x, y))
print(x / y)
print(np.divide(x, y))
print(np.sqrt(x))
Observe que, diferentemente do MATLAB, $*$ é a multiplicação elementar, não a multiplicação de matrizes. Em vez disso, usamos a função dot para calcular produtos internos de vetores, multiplicar um vetor por uma matriz e multiplicar matrizes.
v = np.array([9, 10])
w = np.array([11, 12])
# produto interno
print(v.dot(w))
print(np.dot(v, w))
print(x.dot(v))
print(np.dot(x, v))
print(x.dot(y))
print(np.dot(x, y))
print(x.T)
print('-------------')
# ou
print(np.transpose(x))
Lista de todas as operações: Documentação de Numpy.
Depois de ler isso tudo sobre tensores, você deve estar pensando:
"Beleza, mas... como que redes neurais usam esses tais tensores?".
Por exemplo:1. As entradas podem ser representadas por tensores bi-dimensionais (matrizes), onde cada linha dessa matriz vai representar uma amostra de uma base, equanto cada coluna representa um atributo (também chamada de feature). Por exemplo, no seguinte banco de dados: 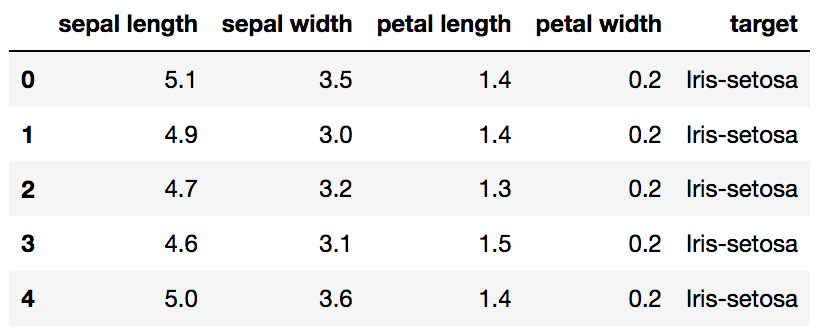 Nós temos 5 amostras (5 linhas) e 4 atributos (
Nós temos 5 amostras (5 linhas) e 4 atributos (sepal length, sepal width, petal length e petal width) - a coluna target nesse banco representa um outro atributo que estamos interessados em identificar para cada amostra.
Considerando imagens as entradas vão ser agora representadas por tensores 4-dimensionais. Em geral, a maioria dos frameworks assumem que esses tensores estão no formato
NxHxWxC, onde:N: representa a quantidade de imagens no seu bancoH: a altura de cada imagemW: a largura de cada imagemC: a quantidade de canais de cada imagem. Imagens em níveis de cinza têm apenas 1 canal, enquanto imagens coloridas possuem 3 canais - vermelho (R), verde (G) e azul (B).Também é comum ver tensores no formato
NxCxHxW, ou seja, os canais da imagem vêm logo após a quantidade de imagens.