O que são redes neurais?



Nesta seção iremos discutir o que são redes neurais e como implementá-las de forma eficiente utilizando matrizes.
Redes neurais podem ser vistas de maneira bastante simplificada como funções matemáticas.
Ideia abstrata
Entradas: x ----> Computação: f ------> Saídas: f(x)Matemática
$f(x) = x \times 2 + 3$
Python
def f(x):
return x * 2 + 3
Similar à funções, as redes neurais possuem entradas e saídas. As entradas são representadas por amostras dos seus dados. As saídas, por sua vez, dependem de que tarefa estamos desempenhando.
Por exemplo, se estamos treinando uma rede neural para classificar imagens que contém cachorros ou gatos, as entradas serão imagens (matrizes de píxels) e as saídas podem ser simplismente um valor binário (1 se tiver um gato na imagem e 0 se tiver um cachorro). A questão é: não sabemos a melhor função f para mapear as entradas para as saídas. Podemos treinar uma rede neural para achar essa função.
Assim, uma simples definição de redes neurais é:
"Redes Neurais são aproximadores de funções"
A diferença é que não sabemos qual a função ótima para representar uma entrada:pythondef f(x):
return x * ? + ??
Não sabemos qual o melhor f possível, mais especificamente, quais valores deveriam ser os valores de ? e ???
Poderíamos tentar várias funções para se ajustar aos dados, quando treinamos rede neurais estamos na verdade buscando aprender quais são os melhores parâmetros (aqui representados por ? e ??) para a uma certa função.
Características das redes neurais
Algumas características específicas de redes neurais como aproximadoras de função são:
- Redes neurais são hierárquicas. Isto é, temos uma série de computações (camadas) colocadas de forma sequencialmente.
Entradas: x ----> Camada: f_1 ------> Camada: f_2 ------> Camada: f_3 ------> Saídas: f(x)- Posso implementar minha camada como eu quiser? Não. O principal requisito de camadas ou partes das redes neurais é que elas devem ser diferenciáveis.
Redes neurais são hierárquicas: são construídas a partir de camadas
Redes Neurais são definidas em termos de camadas. A primeira camada representa as entradas da rede, enquanto a última camada representa as saídas.
Todas as camadas que estão entre as camadas de entrada e saída são chamadas de camadas escondidas (ou hidden layers). Um exemplo de uma Rede Neural com 2 camadas escondidas pode ser vista na figura abaixo:

Sobre as camadas...
Com exceção da camada de entrada, toda camada de uma rede neural é composta pela seguintes propriedades:
número de neurônios: na figura acima, a primeira camada escondida tem 4 neurônios, já a segunda camada escondida tem 3 neurônios, enquanto a camada de saída tem apenas 1. Cada neurônio representa um valor.
parâmetros: cada neurônio recebe como entrada todos as saídas dos neurônios das camadas anteriores. Cada entrada dessa é multiplicada por um peso correspondente. Tais pesos representam o que a Rede Neural pode ajustar para encontrar a solução do problema e são conhecidos como parâmetros.
A imagem acima mostra apenas uma arquitetura possível para uma rede neural. Existem vários outros tipos de arquiteturas e outros tipos de camadas que podemos usar para construir uma rede neural. Neste curso iremos focar nessa arquitetura que se chama MultiLayerPerceptron (MLP).
Todas essas camadas são chamadas camadas densas. A arquitetura MLP é caracterizada por várias camadas densas uma após a outra (várias camadas intermediárias). Apesar de na imagem acima termos escolhido mostrar apenas 2 camadas intermediárias poderíamos ter quantas quiséssemos, com quantos nós quiséssemos!
O número de nós de entrada e de saída são fixos dependendo do problema que estamos tentando resolver. Por exemplo, no problema da classificação de imagens de cachorros e gatos, o número de neurônios de entrada seria o número de píxeis da imagem e o número de neurônios na camada de saída um único neurônio (0 ou 1).
Entendendo a matemática
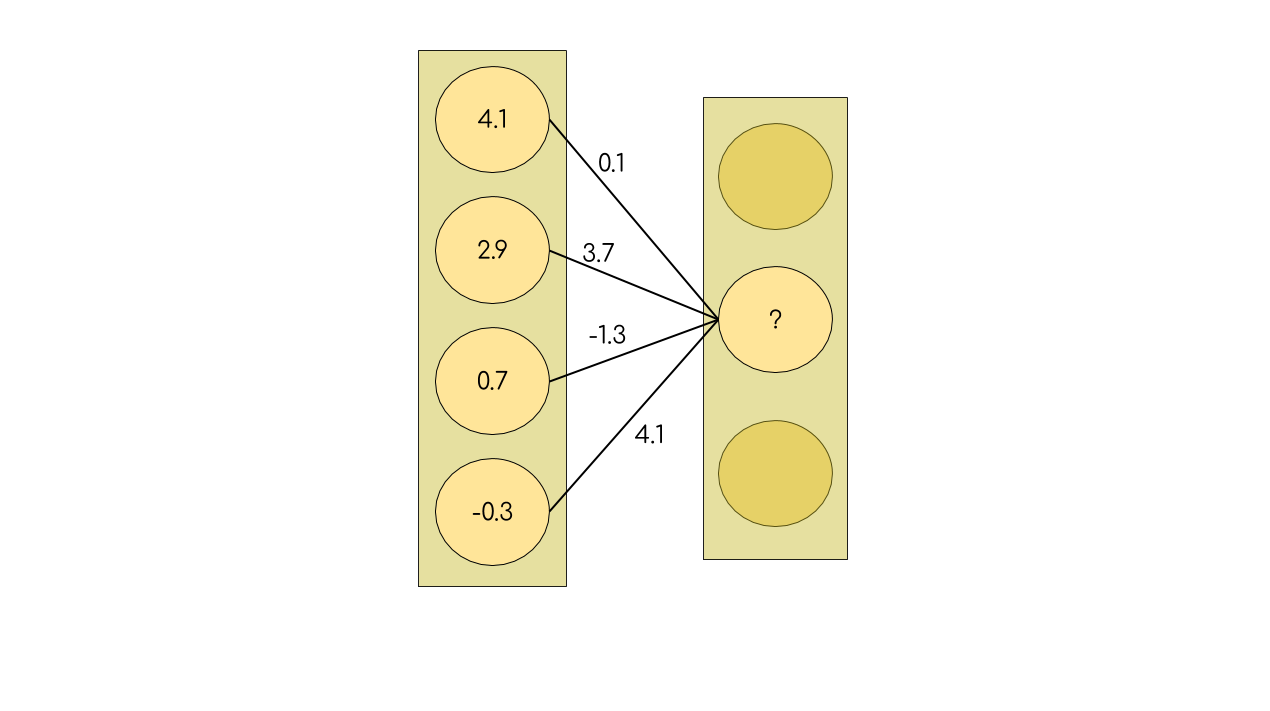
Vamos focar apenas na computação que envolve o segundo nó da segunda camada intermediária:

Cada peso (linha conectando os neurônios da camada anterior a esse neurônio) é um número, e cada nó também representa um número.

Interpretamos esse número como a saída do neurônio, se a saída é um valor alto (> 0) dizemos que o neurônio foi ativado. Como a imagem sugere, utilizamos a saída dos neurônios anteriores para calcular a saída do próximo neurônio. Mas como?
$$SN_j = f(\sum{(SN_i \cdot pij)} + b_j)$$
$SN_j$ = Saída do Neurônio j
$P_ij$ = Peso que liga o neurônio i ao neurônio j
$b_j$ = Bias de do neurônio j

def funcao_de_ativacao(x):
if x > 0:
return x
else:
return 0
def liga_neuronios(saida_neuronios_da_camada_anterior, pesos_neuronio, peso_bias, f):
saida_neuronio = 0
# Soma ponderada dos pesos com a saída
for saida_neuronio_anterior, peso in zip(saida_neuronios_da_camada_anterior, pesos_neuronio):
saida_neuronio += saida_neuronio_anterior * peso
# Adiciona bias
saida_neuronio += peso_bias
# Aplica função de ativação
saida_neuronio = f(saida_neuronio)
return saida_neuronio
# Exemplo da imagem
liga_neuronios([4.1, 2.9, 0.7, -0.3], [0.1, 3.7, -1.3, 4.1], 1, funcao_de_ativacao)
Ok... então para calcular a saída de um neurônio, eu faço a soma ponderada entre os pesos e todas as saídas dos neurônios da camada anterior. Ate aí tudo bem... mas aí eu somo a isso uma coisa chamada bias e depois aplico sobre esse valor uma função de ativação?
Isso!

OBS:Se isolarmos um nó da rede neural temos o que é chamado perceptron.
Função de Ativação
Como o próprio nome indica é uma função matemática. Por enquanto não vamos nos preocupar muito com ela, iremos ver mais sobre funções de ativação na seção 1.5.
Por enquanto só vou dizer 2 coisas:
- A função de ativação que utilizamos no código anterior se chama ReLU, é uma das mais utilizadas e é comumente utilizada entre as camadas intermediárias. Na camada final geralmente não utilizamos função de ativação ou utilizamos alguma outra função (não relu).
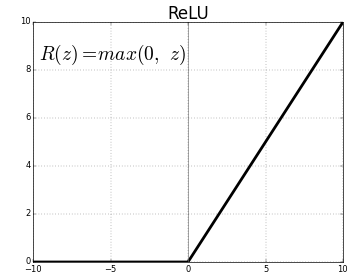
- Como experado de uma função, uma função de ativação transforma uma entrada em alguma outra coisa que obtemos como saída. No caso das funções de ativação é bastante interessante que ela não seja uma reta, por exemplo na imagem acima temos com a ReLU se comporta, ta vendo que ela é tipo um cotovelo dobrado no zero? Isso faz com que a função não seja uma linha reta, e é isso que queremos na função de ativação, não precisa ser um cotovelo, poderia ser uma barraguinha, mas precisamos de curvas!
Bias
O bias é um termo independente da entrada que existe para nos dar mobilidade!
Por exemplo, considere a seguinte função:
y = 2 * x
Essa função tem uma mobilidade limitada, ela passa pela origem (se x = 0, y = 0) e não podemos mudar isso :(. Porém se essa função fosse:
y = 2 * x + bias
Ao modificar o bias, podemos fazer com que a função vá mais para esquerda ou direita, não mais sendo forçada a passar pela origem.
Na nossa rede o bias faz um papel similar! Nos dando liberdade para mover a função que estamos aprendendo, lembra que redes neurais são aproximadores de funções?
Mais informações sobre bias (em inglês) nesse link.
Importante
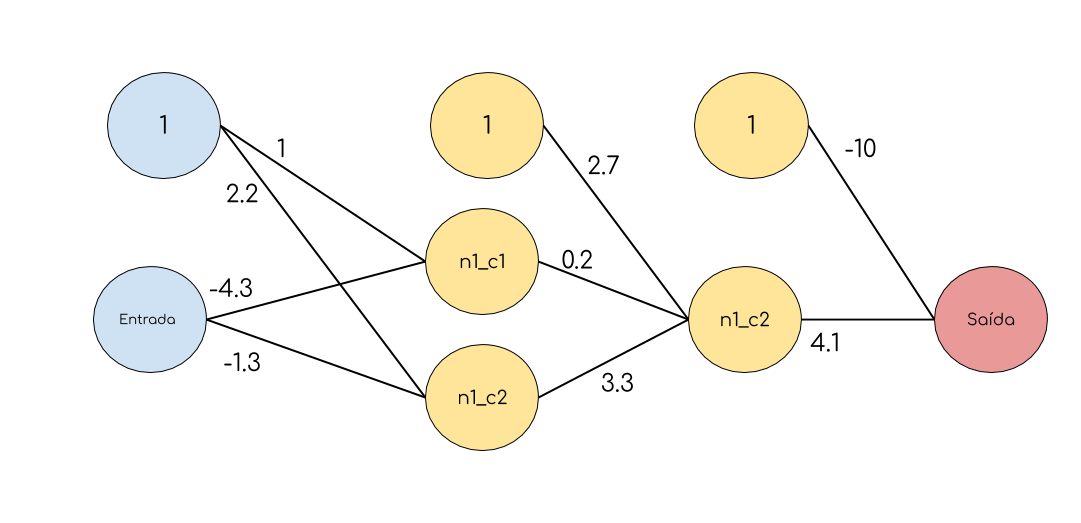
Nos diagramas que mostramos, o bias não era mostrado, por que? Geralmente pra deixar a visualização mais bonitinha não mostramos o bias, abaixo segue nossa rede reural com o bias no diagrama:

O bias é um nó na rede como qualquer outro, porém ele não se conecta aos nós da camada anterior, podemos pensar que seu valor é fixo e igual a 1.
“Se hoje é o Dia da rede neural, ontem eu disse que rede neural... o dia da rede neural é dia da camada, do peso e das funções de ativação, mas também é o dia dos bias. Sempre que você olha uma camada densa, há sempre uma figura oculta, que é um bias atrás, o que é algo muito importante.” - Marianne Rousseff.

# Definimos esse valor! Na prática irá vir de uma base de dados.
entrada = -3
# ------- Primeira camada ---------
n1_c1 = liga_neuronios([entrada], [-4.3], 1, funcao_de_ativacao)
n2_c1 = liga_neuronios([entrada], [-1.3], 2.2, funcao_de_ativacao)
# ------- Segunda camada ---------
n1_c2 = liga_neuronios([n1_c1, n2_c1], [0.2, 3.3], 2.7, funcao_de_ativacao)
# ------- Camada de saída --------
# Na última camada não usamos ReLU, lembra? Podemos simplesmente não usar
# função de ativação, para tal é só usar uma função que não faz nada (função identidade)
# essa função é também denominada como linear nos frameworks de Deep Learning.
def faz_nada(x):
return x
saida = liga_neuronios([n1_c2], [4.1], -10, faz_nada)
print(saida)
A grande sacada das redes neurais é a definição de camadas e como elas se comunicam. Uma rede neural consiste basicamente da mesma computação baseada em camadas onde a entrada de uma camada é a camada imediamente anterior a ela.
Ou seja: uma camada aprende a partir das camadas anteriores!
Isso permite que a rede neural busque modificar os pesos de uma camada de maneira a gerar representações melhores para que a próxima camada tenha acesso a informações mais relevantes pra resolver o problema!
Deixando o código eficiente, bonito e cheiroso
Como a(o) boa(bom) programadora(programador) que você é, deve ter notado que o código anterior é bastante ineficiente!!!
PERGUNTA: mais espeficamente para cada nó em uma rede neural quantas operações são necessárias para calcular sua saída?
Pense a respeito, a resposta segue abaixo...
Para calcular a saída desse nó precisamos cacular a soma ponderada de todos os nós da camada anterior, digamos que a camada anterior tem N nós.
Então precisaríamos de O(N) operações para calcular a saída de um único nó nessa camada.
Então, por exemplo, se tivermos 1 camada de entrada com 100 nós e 2 camadas intermediárias com 200 nós cada, precisaríamos realizar o seguinte número de operações em cada camada:
- camada intermediária 1: 100 * 200 (100 entradas para cada nó, 200 nós) = 20000
- camada intermediária 2: 200 * 200 (200 entradas para cada nó, 200 nós) = 40000
Totalizando: 60000 operações para calcular todas as saídas. Queremos várias camadas na nossa rede, não podemos ser tão lentos :((
Felizmente temos uma solução para deixar esse cálculo mais eficiente!!!

Perceba que:
- Cada nó em uma camada é independente dos demais! Então podemos "paralelizar" essa computação!
- Uma camada L precisa de todos os nós da camada L-1 computados.
Agora vem a sacada:
- Podemos computar todos os valores de uma camada através de multiplicação de matrizes


Por que utilizar multiplicação de matrizes é mais eficiente?
- GPUs manipulam matrizes de forma extremamente eficiente!
- Existem otimizações para lidar com esse tipo de operação de maneira eficiente.
- Multiplicação de matrizes é altamente paralelizável.
!pip3 install numpy
# Programador é bixo preguiçoso então chamamamos numpy de np
# pq numpy é muito grande pra ficar digitando toda hora
import numpy as np
class DenseLayer(object):
def __init__(self, activation_function):
self._weights = []
self.activation_function = activation_function
def set_weights(self, weights):
self._weights = weights
def _add_bias(self, _input):
# Adiciona 1's a entrada
return np.column_stack((np.ones(len(_input)), _input))
def __call__(self, _input):
# adiciona bias a entrada, lembra?
input_with_bias = self._add_bias(_input)
# f_act(entrada * transposta(pesos))
return self.activation_function(np.matmul(input_with_bias, self._weights.transpose()))
# def funcao_de_ativacao(x):
# if x > 0:
# return x
# else:
# return 0
# Agora
def funcao_de_ativacao(x):
return np.where(x > 0, x, 0)
# Definimos esse valor! Na prática irá vir de uma base de dados.
entrada = -3
# ------- Primeira camada ---------
# Antes
# n1_c1 = liga_neuronios([entrada], [-4.3], 1, funcao_de_ativacao)
# n2_c1 = liga_neuronios([entrada], [-1.3], 2.2, funcao_de_ativacao)
# Agora
camada1 = DenseLayer(funcao_de_ativacao)
camada1.set_weights(np.array([[1, -4.3], [2.2, -1.3]]))
# ------- Segunda camada ---------
# Antes
# n1_c2 = liga_neuronios([n1_c1, n2_c1], [0.2, 3.3], 2.7, funcao_de_ativacao)
# Agora
camada2 = DenseLayer(funcao_de_ativacao)
camada2.set_weights(np.array([[2.7, 0.2, 3.3]]))
# ------- Camada de saída --------
# Na última camada não usamos ReLU, lembra? Podemos simplesmente não usar
# função de ativação, para tal é só usar uma função que não faz nada (função identidade)
# essa função é também denominada como linear nos frameworks de Deep Learning.
def faz_nada(x):
return x
# Antes
# saida = liga_neuronios([n1_c2], [4.1], -10, faz_nada)
# Agora
ultima_camada = DenseLayer(faz_nada)
ultima_camada.set_weights(np.array([[-10, 4.1]]))
saida = ultima_camada(camada2(camada1(np.array([entrada]))))
print(saida)
Conclusão
Podemos abstrair redes neurais como aproximadores de funções hierárquicos e diferenciáveis. Para implementar redes neurais de forma eficiente utilizamos multiplicação de matrizes (e outros conceitos de álgebra linear).
Na próxima sessão vamos ver mais sobre a biblioteca Numpy e como utilizá-la para manipular dados.